5.3.
Кодирование символов в ПЭВМ
Под кодированием понимают запись данных с использованием некоторого кода.
Для представления любой информации в современных ЭВМ используются двоичные числа (двоичные коды). При вводе информации в ЭВМ специальными аппаратными и программными средствами каждый символ «преобразуется» в соответствующий двоичный код и записывается в ОЗУ или внешнюю память для последующей обработки. При выводе информации из ЭВМ осуществляется обратное преобразование: двоичный код каждого символа «переводится» во внешнее представление этого символа для его визуального отображения на устройстве вывода (например, принтер по коду символа печатает на бумаге его графический образ).
Числа, в отличие от других символов, при вводе-выводе обрабатываются несколько иначе. После ввода закодированное, но все еще десятичное число программным способом обычно переводится в двоичную систему счисления, чтобы обеспечить эффективное выполнение арифметических операций. Перед выводом осуществляется обратное преобразование.
За основу
кодирования символов в ПЭВМ, как и во многих других ЭВМ, взят код ASCII (American Standard Code for
Information Interchange — американский стандартный код для обмена информацией).
Он введен в
ASCII -кодировка символов приведена в табл. 5.2. Элементами изображенной матрицы являются обозначения символов, а индексами — шестнадцатеричные цифры кодов символов. Для получения шестнадцатеричного кода символа необходимо к цифре-индексу, записанной в соответствующем столбце, приписать справа цифру-индекс, размещенную в соответствующей строке матрицы. Например, символ G имеет код 47Н. Из шестнадцатеричного кода легко получить двоичный код путем записи каждой шестнадцатеричной цифры в двоичной системе счисления (для нашего примера получим 1000111). Если требуется по двоичному коду определить представленный им символ, то следует свернуть этот код в шестнадцатеричное число, разбить его на цифры и найти обозначение символа на пересечении столбца и строки, индексами которых являются старшая и младшая шестнадцатеричные цифры кода соответственно.
ASCII содержит две группы символов:
1) прописные и строчные латинские буквы, цифры, а также специальные знаки, т.е. символы пишущей машинки;
2) управляющие символы, используемые в коммуникационных протоколах, в частности, для передачи команд ПУ.
Эти группы символов разделены в табл. 5.2 двойной линией. Символы пишущей машинки имеют коды 20Н — 7ЕН, а управляющие символы — ООН — 1FH и 7FH.
Относительно символов пишущей машинки специальные пояснения не требуются. Отметим только, что символ с кодом 2DH — это знак «Минус», а с кодом 5FH — знак подчеркивания. Символы с кодами 27Н и 60Н также различаются между собой: первый является апострофом, а второй — знаком тупого (обратного) ударения. Символ " (один символ!) называется кавычками, & — амперсандом, # — знаком номера, ^ — стрелкой вверх, | — вертикальной чертой, ~ — знаком подчеркивания (тильдой), а @ — коммерческим «эт». Символ SP обозначает пробел (Space).
Управляющие символы стандартно интерпретируются следующим образом:
NUL (NULI) — пустой символ, не имеющий значения (может использоваться для задержек);
SOH (Start Of Heading) — начало заголовка (с него начинается передача блока данных);
Таблица
5.2
Таблица символов кода ASCII

STX (Start Of Text) – начало текста (отмечает начало текста, следующего заголовка);
ETX (End of Text) – конец текста (отмечает конец текста и начало контрольного кода);
EOT
(END Of Transmission) – конец передачи;
ENQ (ENQuiry) – запрос подтверждения (запрашивает информацию о статусе удаленной станции);
ACK (ACKnovledge) – подтверждение (подтверждает успешный обмен между станциями);
BEL (BELI) – звонок (инициирует выдачу звукового сигнала);
BS (BackSpace) – возврат на одну позицию (для отмены предыдущего символа);
HT (Horisontal Tab) – горизонтальная табуляция;
LF (Line Feed) – перевод строки;
VT (Vertical Tab) – вертикальная табуляция;
FF (Form Feed) – переход к новой странице (перевод формата);
CR (Carriage Return) – возврат каретки;
SO (Shift Out) – переход на нижний регистр;
SI (Shift In) – переход на верхний регистр;
DLE (Data Link Escape) – завершение сеанса связи;
DCi (Device Control i) – управление устройством i ((i=1,…,4);
NA (Negative AcKnowledge) – ошибка передачи;
SN (SYNchronous idle) - холостые данные синхронной передачи;
ETB (End Transmit Block) – конец передачи блока;
CAN (CANcel) - отмена (сигнализирует об ошибке передачи);
EM (End of Medium) – конец носителя данных (сигнализирует о физическом конце источника данных);
SUB (SUBstitute) – подстановка (для замены символов);
ESC (ESCape) – переход (изменение интерпретации последующих кодов);
FS (File Separator) – разделитель файлов;
GS (Group Separator) – разделитель групп;
RS (Record Separator) – разделитель записей;
US (Unit Separator) – разделитель элементов;
В той или иной ЭВМ могут использоваться не все управляющие символы, а задействованные могут интерпретироваться несколько иначе. Использование и интепретацию управляющих символов в IBM-совместимых ПЭВМ мы рассмотрим в следующем подразделе, когда станет ясно, как их вводить с клавиатуры.
С учетом легкости формирования символов из-за графического характера ПУ ПЭВМ (т.е. возможности формировать различные символы по точкам) ASCII совершенно недостаточен для представления многих полезных символов по причине того, что он содержит всего 128 кодов. Потребность в большем числе кодов особенно ощущается в случае необходимости работать на языках, алфавиты которых отличны от английского. С другой стороны, 7-разрядный двоичный код все равно занимает байт (8 разрядов). При коммуникациях между удаленными станциями дополнительный бит используется для контроля по четности (нечетности). В большинстве же ПЭВМ это не требуется и один бит в коде каждого символа остался бы незадействованным. По указанным причинам фирма IBM расширила ASCII таким образом, что каждый символ стал представляться 8-разрядным двоичным кодом. Это позволило закодировать уже 256 символов.
Зарегистрированная фирмой ШМ кодировка (кодовая страница 437, называемая американской кодировкой) используется на всех IBM-совместимых ПЭВМ во всем мире и представлена в табл. 5.3. Вместо наименований символов в ячейках матрицы даны их графические изображения на экране дисплея. Следует иметь в виду, что для получения графических изображений всех символов на экране дисплея необходимо! осуществить запись их кодов непосредственно в видеопамять или использовать одно из прерываний нижнего уровня. Попытка вывести изображение символа при помощи высокоуровневых средств файловой системы DOS не приведет к достижению желаемого результата, если символ оказывает управляющее воздействие на дисплей или трактуется DOS (либо другим используемым в настоящий момент программным продуктом) особым образом. Например, если попытаться вывести символ с кодом 07Н (BEL), то вместо появления на экране дисплея крупной точки будет выдан звуковой сигнал. Аналогично при попытке вывести символ с кодом 09Н (НТ, TAB) вместо его изображения реакция дисплея будет иной: произойдет перемещение курсора вправо до очередной позиции табуляции. На вводе символов с клавиатуры мы остановимся особо в следующем подразделе (в этом случае также имеются определенные тонкости).
Расширенный код ASCII полностью включает в себя стандарт ASCII (левая половина матрицы) и дополнительно содержит 128 кодов с единицей в старшем бите (правая половина матрицы). Среди дополнительных символов часто используемые (но не все) буквы ряда европейских алфавитов (немецкого, французского, финского и др.), буквы греческого алфавита, математические символы и символы псевдографики. Последние можно использовать при вычерчивании простейших схем и таблиц (см. столбцы В, С и D). В качестве псевдографических допускается применять и некоторые (незадействованные в ПЭВМ и DOS) управляющие символы, которые будут перечислены в следующем подразделе.
Отметим, что символ с кодом FFH (как и ООН) не задействован и является «пустым».
В настоящее время под кодом ASCII применительно к ПЭВМ часто понимают описанное расширение ASCII.
Для использования в Европе больше подходит кодовая страница 850 (многоязыковая кодировка), содержащая как латиницу, так и большинство букв европейских, а также северо- и южно-американских алфавитов. В жертву же принесены буквы греческого алфавита и некоторые символы псевдографики, замена которых наименее ощутима. К таким псевдографическим символам относятся так называемые полуторные символы (соединения одинарных и двойных линий), изменение представления которых может исказить лишь углы диалоговых окон на экране.
Нередко для практических целей требуется иметь информацию о кодах символов в десятичной или двоичной системах счисления. Поэтому в табл. 5.4 мы представили соответствие между кодами символов в шестнадцатеричной, двоичной и десятичной системах счисления. Эта таблица аналогична табл. 5.3, но вместо графических изображений символов проставлены их десятичные коды, а индексирование элементов матрицы может вестись не только в шестнадцатеричной, но и в двоичной системе счисления. Например, по табл. 5.3 можно установить, что шестнадцате-ричным кодом символа М будет 4DH. Тогда на основании табл. 5.4 легко определить, что код этого символа в двоичной системе счисления равен 01001101, а в десятичной — 77.
Для представления символов кириллицы (букв русского алфавита) было предложено много модификаций кодовой таблицы IBM. Все они основываются на подмене некоторых символов символами кириллицы и иногда на изменении кодировки ряда символов. ГОСТом закреплена так называемая основная кодировка, в которой символы кириллицы размещены в столбцах В, С, D, Е и частично F, а символы псевдографики перенесены в столбцы 8, 9 и А. Однако эта таблица распространения не получила, так как при ее использовании не могут нормально функционировать англоязычные программные продукты, выводящие на экран дисплея псевдографические символы (вместо рамок, окон и таблиц получаются неприятные изображения, состоящие из русских букв).
Для устранения этого недостатка Брябрин В.М. и Чижов АА. предложили альтернативную кодировку, в которой символы псевдографики имеют те же коды, что и в таблице IBM, а русские буквы занимают столбцы 8, 9, А, Е и частично F (см. табл. 5.5), замещая буквы европейских алфавитов, буквы греческого алфавита и математические символы. В альтернативной кодировке столбец F содержит некоторые дополнительные символы псевдографики и другие символы.
Таблица
5.3
Таблица символов расширенного кода ASCII
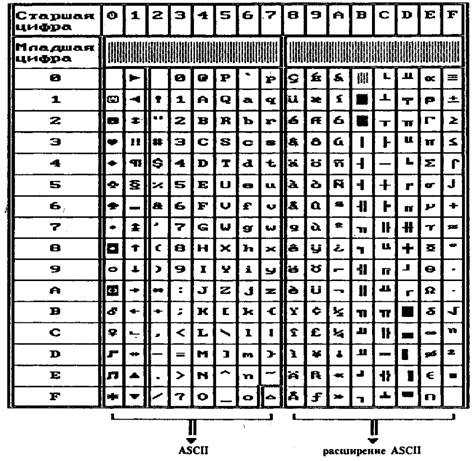
Рассматриваемый вариант кодировки не изменяет расположения в таблице символов псевдографики (столбцы В, С и D). Поэтому англоязычные программные продукты функционируют нормально. Однако русские буквы размещены несколько неудобно: их нормальная последовательность прерывается псевдографическими символами, вследствие чего в общем случае нельзя получить код следующей по алфавиту буквы путем прибавления единицы к коду очередной буквы. Это несколько ограничивает возможности манипулирования русскими буквами в развитых языках программирования. Тем не менее лексикографический (алфавитный) порядок следования букв все же сохранен, что в определенной степени сглаживает отмеченный недостаток альтернативной кодировки, позволяя, по крайней мере, сортировать слова в алфавитном порядке. До недавнего времени альтернативная кодировка была в СССР самой распространенной, да и сейчас широко применяется на отечественных ПЭВМ:
На машинах класса AT и старше альтернативную кодировку сменил ее модифицированный вариант (см. табл. 5.6). Отличие этой кодировки от прототипа состоит в том, что столбец F кодовой таблицы полностью заимствован из кодовой таблицы IBM. Целью такого «отката» назад является обеспечение большей совместимости данной таблицы с IBM-таблицей. Плата за это заключается в том, что из кодировки исключены русская буква Ё и ряд других полезных символов, включая стрелки.
Мы уже говорили о том, что фирма IBM недавно зарегистрировала кодовую страницу для СССР (теперь — СНГ). Кодировка символов в ней основывается на альтернативном варианте. Отличия состоят лишь в том, что в столбце F находятся уникальные буквы украинского и белорусского алфавитов, а также некоторые символы из кодовой таблицы IBM. Эта кодировка Представлена в табл. 5.7.
Заметим, что буквы латиницы и кириллицы одинакового начертания во всех рассмотренных кодировках имеют разное представление. Это связано с необходимостью обеспечить лексикографический порядок следования букв. Факт различия кодов одноименных букв разных алфавитов нужно обязательно учитывать при работе на ПЭВМ.
Таблица 5.14
Соответствие шестнадцатеричных, двоичных и десятичных чисел
|
Старшие цифры |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
16-я |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
А |
В |
С |
В |
Е |
F |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2-е |
0000 |
0001 |
ООЮ |
ООН |
0100 |
0101 |
ОНО |
0111 |
1000 |
1001 |
1010 |
1011 |
1100 |
1101 |
1110 |
1111 |
|
|
Младшие |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
цифры |
|
|
|
|
|
|
|
|
|
||||||||
|
16-я |
2-е |
|
|
|
|
|
|
|
|
||||||||
|
0 |
0000 |
0 |
16 |
32 |
48 |
64 |
80 |
96 |
112 |
128 |
144 |
160 |
176 |
192 |
208 |
224 |
240 |
|
1 |
0001 |
1 |
17 |
33 |
49 |
65 |
81 |
97 |
113 |
129 |
145 |
161 |
177 |
193 |
209 |
225 |
241 |
|
2 |
0010 |
2 |
18 |
34 |
50 |
66 |
82 |
98 |
114 |
130 |
146 |
162 |
178 |
194 |
210 |
226 |
242 |
|
3 |
ООН |
3 |
19 |
35 |
51 |
67 |
83 |
99 |
115 |
131 |
147 |
163 |
179 |
195 |
211 |
227 |
243 |
|
4 |
0100 |
4 |
20 |
36 |
52 |
68 |
84 |
100 |
116 |
132 |
148 |
164 |
180 |
196 |
212 |
228 |
244 |
|
5 |
0101 |
5 |
21 |
37 |
53 |
69 |
85 |
101 |
117 |
133 |
149 |
165 |
181 |
197 |
213 |
229 |
245 |
|
6 |
оно |
6 |
22 |
38 |
54 |
70 |
86 |
102 |
118 |
134 |
150 |
166 |
182 |
198 |
214 |
230 |
246 |
|
7 |
0111 |
7 |
23 |
39 |
55 |
71 |
87 |
103 |
119 |
135 |
151 |
167 |
183 |
199 |
215 |
231 |
247 |
|
8 |
1000 |
8 |
24 |
40 |
56 |
72 |
88 |
104 |
120 |
136 |
152 |
168 |
184 |
200 |
216 |
232 |
248 |
|
9 |
1001 |
9 |
25 |
41 |
57 |
73 |
89 |
105 |
121 |
137 |
153 |
169 |
185 |
201 |
217 |
233 |
249 |
|
A |
1010 |
10 |
26 |
42 |
58 |
74 |
90 |
106 |
122 |
138 |
154 |
170 |
186 |
202 |
218 |
234 |
250 |
|
В |
1011 |
11 |
27 |
43 |
59 |
75 |
91 |
107 |
123 |
139 |
155 |
171 |
187 |
203 |
219 |
235 |
251 |
|
С |
1100 |
12 |
28 |
44 |
60 |
76 |
92 |
108 |
124 |
140 |
156 |
172 |
188 |
204 |
220 |
236 |
252 |
|
E |
1101 |
13 |
29 |
45 |
61 |
77 |
93 |
109 |
125 |
141 |
157 |
173 |
189 |
205 |
221 |
237 |
253 |
|
Е |
1110 |
14 |
30 |
46 |
62 |
78 |
93 |
НО |
126 |
142 |
158 |
174 |
190 |
206 |
222 |
238 |
254 |
|
F |
1111 |
15 |
31 |
47 |
62 |
79 |
95 |
111 |
127 |
143 |
159 |
175 |
191 |
207 |
223 |
239 |
255 |
Таблица
5.5
Таблица
символов альтернативной кодировки
|
Старшая цифра |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
A |
B |
C |
D |
E |
F |
|
Младшая цифра |
|
|
||||||||||||||
|
0 |
|
► |
|
0 |
|
P |
` |
p |
А |
Р |
а |
░ |
∟ |
╨ |
р |
Ё |
|
1 |
☺ |
◄ |
|
1 |
A |
Q |
a |
q |
Б |
С |
б |
▒ |
┴ |
╤ |
с |
ё |
|
2 |
☻ |
↕ |
" |
2 |
B |
R |
b |
r |
В |
Т |
в |
▓ |
┬ |
╥ |
т |
|
|
3 |
♥ |
‼ |
# |
3 |
C |
S |
c |
s |
Г |
У |
г |
│ |
├ |
╙ |
у |
|
|
4 |
♦ |
¶ |
$ |
4 |
D |
T |
d |
t |
Д |
Ф |
д |
┤ |
─ |
╘ |
ф |
|
|
5 |
|
§ |
٪ |
5 |
E |
U |
e |
u |
Е |
Х |
е |
╡ |
┼ |
╒ |
х |
|
|
6 |
|
▬ |
& |
6 |
F |
V |
f |
v |
Ж |
Ц |
ж |
╢ |
╞ |
╓ |
ц |
→ |
|
7 |
|
↕ |
׳ |
7 |
G |
W |
g |
w |
З |
Ч |
з |
╖ |
╟ |
╫ |
ч |
← |
|
8 |
|
↑ |
( |
8 |
H |
X |
h |
x |
И |
Ш |
и |
╕ |
╚ |
╪ |
ш |
↓ |
|
9 |
|
↓ |
) |
9 |
I |
Y |
i |
y |
Й |
Щ |
й |
╣ |
╔ |
┘ |
щ |
↑ |
|
A |
|
→ |
* |
: |
J |
Z |
j |
z |
К |
Ъ |
к |
║ |
╩ |
|
ъ |
÷ |
|
B |
♂ |
← |
+ |
; |
K |
[ |
k |
{ |
Л |
Ы |
л |
╗ |
╦ |
■ |
ы |
± |
|
C |
♀ |
|
, |
< |
L |
\ |
l |
: |
М |
Ь |
м |
╝ |
╠ |
▄ |
ь |
|
|
D |
♪ |
↔ |
- |
= |
M |
] |
m |
} |
Н |
Э |
н |
╜ |
═ |
▌ |
э |
¤ |
|
E |
♫ |
▲ |
. |
> |
N |
^ |
n |
̃ |
О |
Ю |
о |
╛ |
╬ |
▐ |
ю |
■ |
|
F |
☼ |
▼ |
/ |
? |
O |
_ |
o |
⌂ |
П |
Я |
п |
¬ |
╧ |
▀ |
я |
|
Все представленные кодировки с кириллицей имеют следующий недостаток: программные продукты, выдающие сообщения и принимающие информацию от пользователя на европейских языках, не могут функционировать нормально. Поэтому такие программы неудобно использовать в СНГ, а кодовые страницы с кириллицей не могут быть приняты в европейских странах. Усилиями ряда ведущих советских программистов и руководителей совместных предприятий найдено компромиссное решение, при котором в кодовой таблице остаются буквы европейских алфавитов, добавляются символы кириллицы, а в жертву приносится часть псевдографических символов. Эта кодировка получила название европейской и также зарегистрирована фирмой IBM. Она включает латиницу, кириллицу, те же буквы европейских алфавитов, что и кодовая страница 437, а также только те символы псевдографики, которые содержатся в кодовой странице 850. Заметным недостатком данной таблицы является нарушение лексикографического порядка следования букв кириллицы.
На смену базирующимся на ASCII кодировкам символов в ПЭВМ в скором времени, видимо, придет недавно созданная 16-битная кодировка Unicode. Она содержит 65536 символов, а именно:
— практически все символы большинства языков народов мира;
— элементы китайских, корейских и японских иероглифов, позволяющие строить любые иероглифы;
— специальные символы (знаки пунктуации, транскрипции, математические и технические символы, а также псевдографические символы);
Таблица
5.6
Таблица
символов модифицированной
альтернативной кодировки
|
Старшая цифра |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
A |
B |
C |
D |
E |
F |
|
Младшая цифра |
|
|
||||||||||||||
|
0 |
|
► |
|
0 |
|
P |
` |
p |
А |
Р |
а |
░ |
∟ |
╨ |
р |
≡ |
|
1 |
☺ |
◄ |
|
1 |
A |
Q |
a |
q |
Б |
С |
б |
▒ |
┴ |
╤ |
с |
± |
|
2 |
☻ |
↕ |
" |
2 |
B |
R |
b |
r |
В |
Т |
в |
▓ |
┬ |
╥ |
т |
≥ |
|
3 |
♥ |
‼ |
# |
3 |
C |
S |
c |
s |
Г |
У |
г |
│ |
├ |
╙ |
у |
≤ |
|
4 |
♦ |
¶ |
$ |
4 |
D |
T |
d |
t |
Д |
Ф |
д |
┤ |
─ |
╘ |
ф |
|
|
5 |
|
§ |
٪ |
5 |
E |
U |
e |
u |
Е |
Х |
е |
╡ |
┼ |
╒ |
х |
|
|
6 |
|
▬ |
& |
6 |
F |
V |
f |
v |
Ж |
Ц |
ж |
╢ |
╞ |
╓ |
ц |
÷ |
|
7 |
|
↕ |
׳ |
7 |
G |
W |
g |
w |
З |
Ч |
з |
╖ |
╟ |
╫ |
ч |
≈ |
|
8 |
|
↑ |
( |
8 |
H |
X |
h |
x |
И |
Ш |
и |
╕ |
╚ |
╪ |
ш |
ە |
|
9 |
|
↓ |
) |
9 |
I |
Y |
i |
y |
Й |
Щ |
й |
╣ |
╔ |
┘ |
щ |
- |
|
A |
|
→ |
* |
: |
J |
Z |
j |
z |
К |
Ъ |
к |
║ |
╩ |
|
ъ |
- |
|
B |
♂ |
← |
+ |
; |
K |
[ |
k |
{ |
Л |
Ы |
л |
╗ |
╦ |
■ |
ы |
|
|
C |
♀ |
|
, |
< |
L |
\ |
l |
: |
М |
Ь |
м |
╝ |
╠ |
▄ |
ь |
© |
|
D |
♪ |
↔ |
- |
= |
M |
] |
m |
} |
Н |
Э |
н |
╜ |
═ |
▌ |
э |
z |
|
E |
♫ |
▲ |
. |
> |
N |
^ |
n |
̃ |
О |
Ю |
о |
╛ |
╬ |
▐ |
ю |
■ |
|
F |
|
▼ |
/ |
? |
O |
_ |
o |
⌂ |
П |
Я |
п |
¬ |
╧ |
▀ |
я |
|
— 5000 жест для частного использования;
— резерв из 30000 мест.
В Unicode не входят управляющие символы, однако возможность их использования предусмотрена с помощью данной кодировки разрешится множество проблем, связанных с ограниченностью набора доступных символов.
Для удобства вычерчивания линий и таблиц, а также заполнения фона в текстовых редакторах мы выделили соответствующие символы псевдографики из рассмотренных кодировок и представили их (вместе с кодами) в табл. 5.8. Эти символы инвариантны ко всем четырем явно приведенным в данном подразделе кодировкам. Псевдографические символы разбиты на группы по функциональному признаку и изображены в центральном поле таблицы. В левом поле с той же расстановкой записаны их коды в десятичной, в правом — в шестнадцатеричной системе счисления. Порядок их ввода с клавиатуры будет обсуждаться в следующем подразделе. Заметим, что в эту таблицу затесались и четыре управляющих символа, которые не оказывают управляющих воздействий ни на принтер, ни на дисплей. Однако они могут не печататься на некоторых типах принтеров, в особенности, в сочетании с драйверами кириллицы. Эти вопросы можно уточнить по документации на Ваш принтер, где содержатся все поддерживаемые им кодовые таблицы.